Performing a root cause analysis
Hello! In this week’s newsletter I write about performing a root cause analysis, and how that helps us prevent having the same data incidents over and over again.
There’s also links to articles on using AI to build a robust testing framework, context engineering, and how the data warehouse got its name.
Performing a root cause analysis
Do you have many similar data incidents impacting your team and/or pipelines?
If so, do you know what the root causes are? Or, are you just continually working around the problem?
If that’s you, you should perform a root cause analysis.
A root cause analysis is a process for identifying the fundamental cause(s) of a problem. It is used in many industries for many different types of problems, and is equally useful in helping us identify the cause(s) of our data reliability problem.
There are a few techniques we can use for a root cause analysis, including the 5 whys and the one I’m going to show today, known as the fishbone diagram.
The way it works is:
- You put the problem statement at the head of the fish
- From the backbone you add a bone for each major category of causes
- For each category, brainstorm potential causes that could contribute to the problem, and add them as bones from the category line
For example, you’ll likely find that one of your most common root causes for data incidents is an upstream breaking schema change, where some data you relied on had it’s schema changed in an incompatible way (for example, removing a field you depended on) that broke your data application.
If we use a fishbone diagram to do a root cause analysis on that we will get something that looks like this:
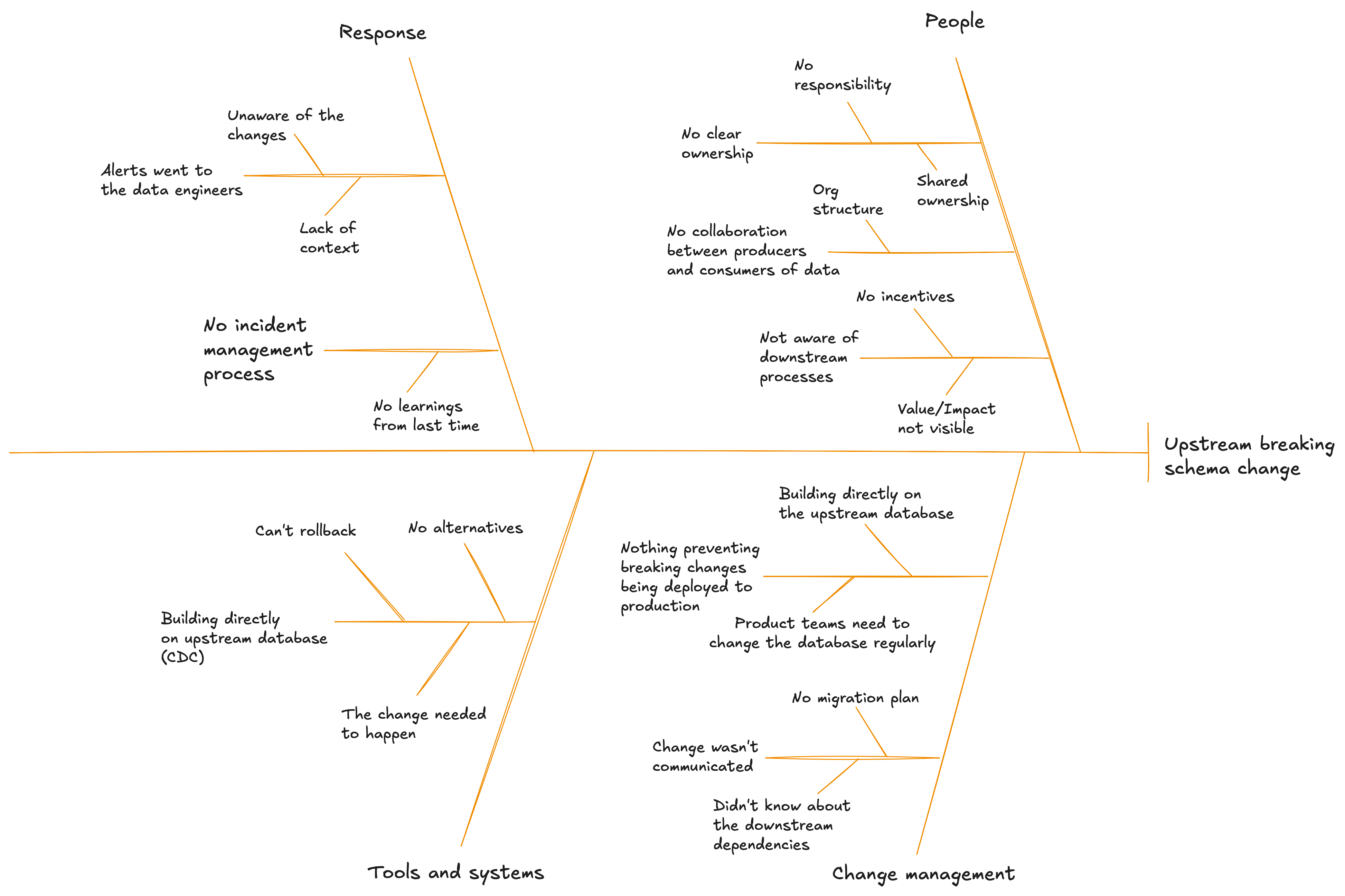
(If you want the fish-like version, see here.)
{kind=link}
Don’t just use mine though!
Perform this analysis yourself, based on the root causes you’ve seen from your data incidents.
Get people outside of your team involved too. The stakeholders, the data consumers, and the data producers.
Not only does that help continue to build those relationships, they will undoubtably have great input, while also learning more about what you see from your point of view.
It’s likely when you’re done you will have something similar to what I have, as while our data is different, our problems are often the same. But the process itself is still important.
With this deep understanding of the problem and it’s root causes, you can now start thinking about how to solve them, preventing the same data incidents from occurring in future, and allowing you to spend less time firefighting, and more time delivering.
Interesting links
Using AI to build a robust testing framework by Mikkel Dengsøe
Part 2 of a nice series on using AI in data engineering.
The New Skill in AI is Not Prompting, It’s Context Engineering by Philipp Schmid
Context Engineering is
- A System, Not a String: Context isn’t just a static prompt template. It’s the output of a system that runs before the main LLM call.
- Dynamic: Created on the fly, tailored to the immediate task. For one request this could be the calendar data for another the emails or a web search.
- About the right information, tools at the right time: The core job is to ensure the model isn’t missing crucial details (“Garbage In, Garbage Out”). This means providing both knowledge (information) and capabilities (tools) only when required and helpful.
- where the format matters: How you present information matters. A concise summary is better than a raw data dump. A clear tool schema is better than a vague instruction.
Sounds like data engineering.
How Data Warehouse Got Its Name by Bill Inmon
It’s an interesting story, before things get a bit spicy with this seemingly throwaway comment within the article:
And I am still discovering things about data warehouse today. The need for ETL, not ELT is one recent vintage discovery. The abortion that is a data lake is another discovery. Data lakes have set our industry back a decade. Or more.
Which I agree with, and hope to see this elaborated on more by Bill in a future article.
Being punny 😅
To dentists, X-rays are really just tooth pics.
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
Enjoy your weekend.
Andrew