What happens when writing data is cheap
Hey all, hope you had a good week. I was in Berlin for Google I/O Connect and attended some great workshops!
Speaking of workshops, I’m considering running another one of my Implementing Data Contracts workshops, either in-person (London?) or online. I’d only put the effort in if there was enough demand. Let me know if you would be interested by replying to this email :)
On to the newsletter, today I look at what happens when writing data is cheap.
There’s also links to articles on the value of data compared to code in the AI era, Uber’s new framework for data management, and praising normal engineers.
What happens when writing data is cheap
I started working in data in the era of Hadoop. It was a great technical leap forward, but led to a damaging change in mindset that still persists today.
Hadoop, and specifically, HDFS, freed us from the limitation of databases constrained by the size of the on-prem machine that hosted it, allowing us to store data at significantly reduced costs, and provided new tools to process this data that was now stored across many, low-cost machines.
We called this a data lake.
However, because storage became relatively cheap, we stopped applying discipline to the data we stored. We lowered the barriers of entry for data writers, harvesting as much data as we could.
We stopped worrying about schemas when writing data, saying it’s fine, we’ll just apply the schema on read…
But by making writing data cheap, we made reading it expensive.
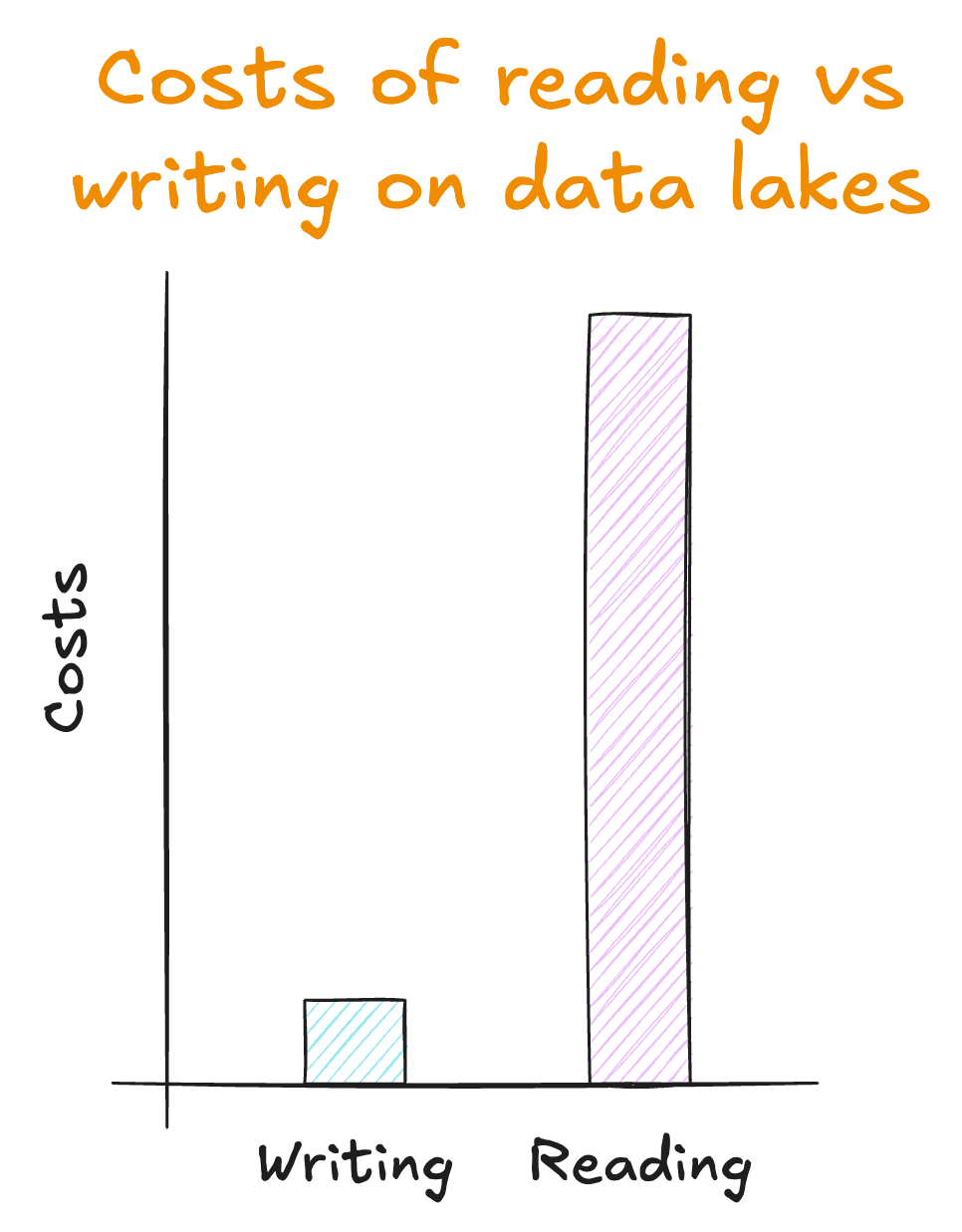
For a start, it was almost impossible to know what data was in there and how it was structured. It lacked any documentation, had no set expectations on its reliability and quality, and no governance over how it was managed.
Then, once you did find some data you wanted to use, you needed to write MapReduce jobs using Hadoop or, later, Apache Spark. But this was very difficult to do – particularly at any scale – and only achievable by a large team of specialist data engineers.
Even then, those jobs tended to be unreliable and have unpredictable performance.
Actually using this data became prohibitively expensive. So much so, it was hardly worth the effort.
That’s why people started calling them data swamps, rather than data lakes.
Although some of us have moved away from data lakes, schema on read, etc, this mindset is still prevalent in our industry.
We still feel we need writing data to be cheap.
We still accept that a large portion of our time and money will be spent “cleaning” this data, before it can be put to work.
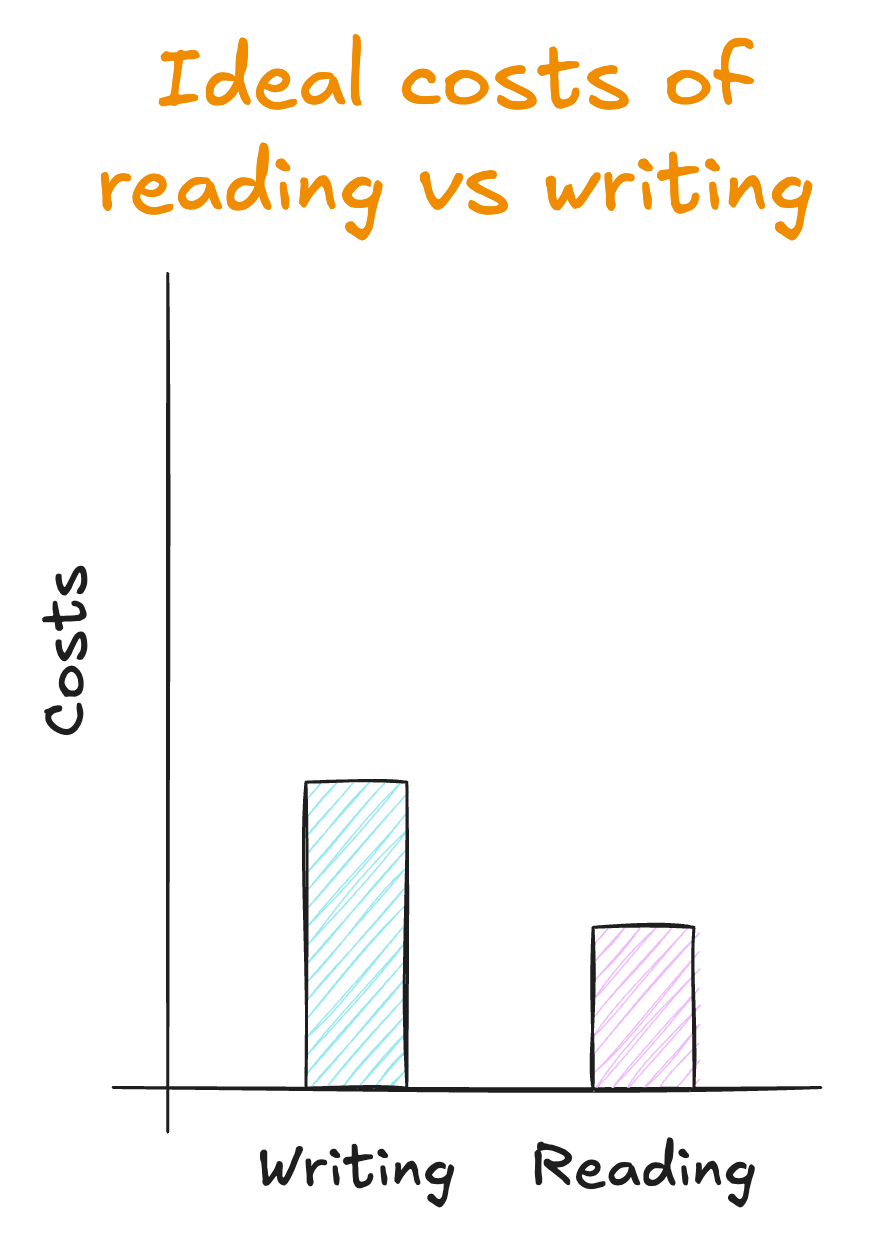
But, if the data is as valuable as we say it is, why can’t we argue for a bit more discipline to be applied when writing data?
Why can’t we apply schemas to our data on publication? We use strongly-typed schemas every other time we create an interface between teams/owners, including APIs, infrastructure as code, and code libraries.
How much would costs be reduced for the company if that was the case? We can total up the time spent cleaning the data, the time spent responding to incidents, the opportunity costs of being unable to provide reliable data to the rest of the company.
Is the ROI positive?
I’d bet it is.
I was reminded triggered(!) by this when chatting to Kris Peeters and Jacek Majchrzak on the The Data Playbook, recorded live at Data Mesh Live a few weeks ago. You can watch us discuss this, data mesh, data contracts, and a whole lot more on YouTube.
Interesting links
Why Data is More Valuable than Code by Tomasz Tunguz
Related to my post above. If data is more valuable than code then we need to treat it with at least the same discipline as we do with code.
From Archival to Access: Config-Driven Data Pipelines by Abhishek Dobliyal and Aakash Bhardwaj at Uber
Interesting read on how the team at Uber designed their archival and retrieval framework. I particularly like the config-driven approach which they say “allows for seamless automation, minimizing human error and improving data validation”.
I also like they took this further and built a web UI to make “data management accessible even to non-technical users”.
In Praise of “Normal” Engineers by Charity Majors
Great post looking at creating the right environments for “normal” engineers to thrive. There’s a few things you should focus on, and platforms are one of them:
Wrap designers and design thinking into all the touch points your engineers have with production systems. Use your platform engineering team to think about how to empower people to swiftly make changes and self-serve, but also remember that a lot of times people will be engaging with production late at night or when they’re very stressed, tired, and possibly freaking out. Build guard rails. The fastest way to ship a single line of code should also be the easiest way to ship a single line of code.
That applies to data platforms just as much as it does to software engineering platforms.
Upcoming webinar
On July 16th I’ll be joining Jack Vanlightly and Shruthi Panicker from Confluent to discuss How to Implement Data Contracts: A Shift Left to First-Class Data Products.
In this practical webinar we’ll dive into:
- Data Contract Fundamentals: Explore how data contracts enable higher-quality data efficiently, and the pros and cons of various implementation approaches
- Going from Theory to Practice: Learn how to implement data contracts using Confluent
- Data Contracts and Data Products: See first-hand how to build reusable, reliable, and real-time data products represented as streams or analytical tables using DSP capabilities such as Apache Flink and Tableflow
Being punny 😅
Thank you for calling for basic kite advice, please hold the line. Goodbye.
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
Enjoy your weekend.
Andrew